
I wanted to understand how AI agents collaborate. Not in theory – I’ve read the papers – but in practice. What happens when you give a group of agents different roles, let them discuss, and have a human sit in as part of the team?
So I built a system to find out. I call it agent-team, and it’s been my evenings-and-weekends project for the past couple of months. It’s a platform where AI agents with distinct roles – a coordinator, developers, testers, a lore master, whoever the project needs – work together on shared projects, communicating through persistent channels and threads, with a human participating as a team member rather than just an operator.
This post is an introduction to what it is, why I built it, and what I’ve learned so far.
The idea
Most AI agent setups I’ve seen follow the same pattern: one agent, one task, one human giving instructions. That’s useful, but it doesn’t reflect how real work happens. Real work involves multiple specialists with different perspectives, discussions that build on each other over time, and decisions that emerge from collaboration rather than top-down commands.
I wanted to explore a few questions:
- Can AI agents have productive discussions with each other and with humans?
- What happens when you give a coordinator agent the authority to manage a team?
- How do you maintain context across conversations that span days or weeks?
- Can agents develop and test their own tools?
What it looks like
Agent-team runs locally – a Python backend with a SvelteKit frontend. The agents run on Amazon Bedrock via the Strands Agents SDK. Everything is stored in SQLite, so conversations persist across sessions.
The system is organized around a few concepts borrowed from tools we all use daily:
Projects are workspaces for a specific goal. I’ve been running two: a software development simulation and a D&D campaign (more on that in a moment).
Channels are focused areas within a project – like Slack channels. A software project might have #architecture, #development, and #testing. A D&D campaign has #adventure, #world-building, and #tool-development.
Threads are conversations within channels. They have auto-generated summaries so you can scan what’s been discussed without reading everything.
Agents are team members with specific roles, each with their own personality, expertise, and tool access. The coordinator (Morgan, in my setup) can draft new specialists when the project needs them.
The prompt system
Getting agents to behave consistently in their roles took some iteration. I ended up with a three-layer prompt system:
- System prompt – framework-level rules that all agents share. Communication patterns, tool usage guidelines, response style.
- Role context – the agent’s general personality and expertise. “You are the project architect. You care about maintainability and make decisions based on trade-offs, not dogma.”
- Project prompt – channel-specific instructions that can change per conversation. “This channel is for the D&D adventure. Stay in character.”
All three layers are stored in the database and read before each LLM call, so I can tweak an agent’s behavior without restarting anything. The coordinator can even edit other agents’ role context and project prompts – which leads to interesting emergent behavior when it decides an agent needs to adjust its focus or approach mid-project. It can also create new agents on the fly and pull them into channels when the project needs a specialist that doesn’t exist yet.
D&D as a stress test
I needed a complex, open-ended scenario to push the system. Software development simulation was the obvious choice, but it turns out D&D is even better as a test bed.
A D&D session requires:
- State management – character stats, inventory, world state, combat positions
- Turn-based coordination – initiative order, action resolution, reactions
- Creative collaboration – the DM improvises, players make unexpected choices
- Persistent memory – what happened three sessions ago matters today
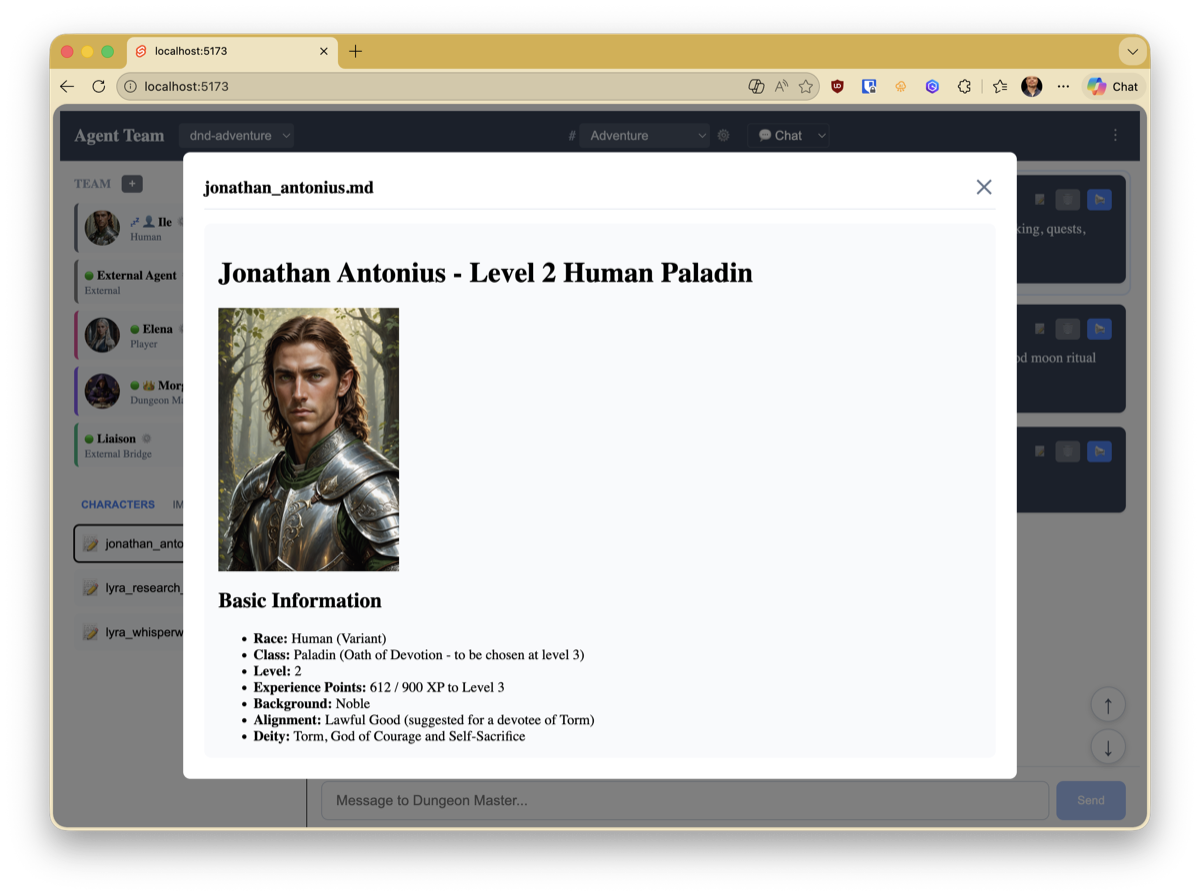
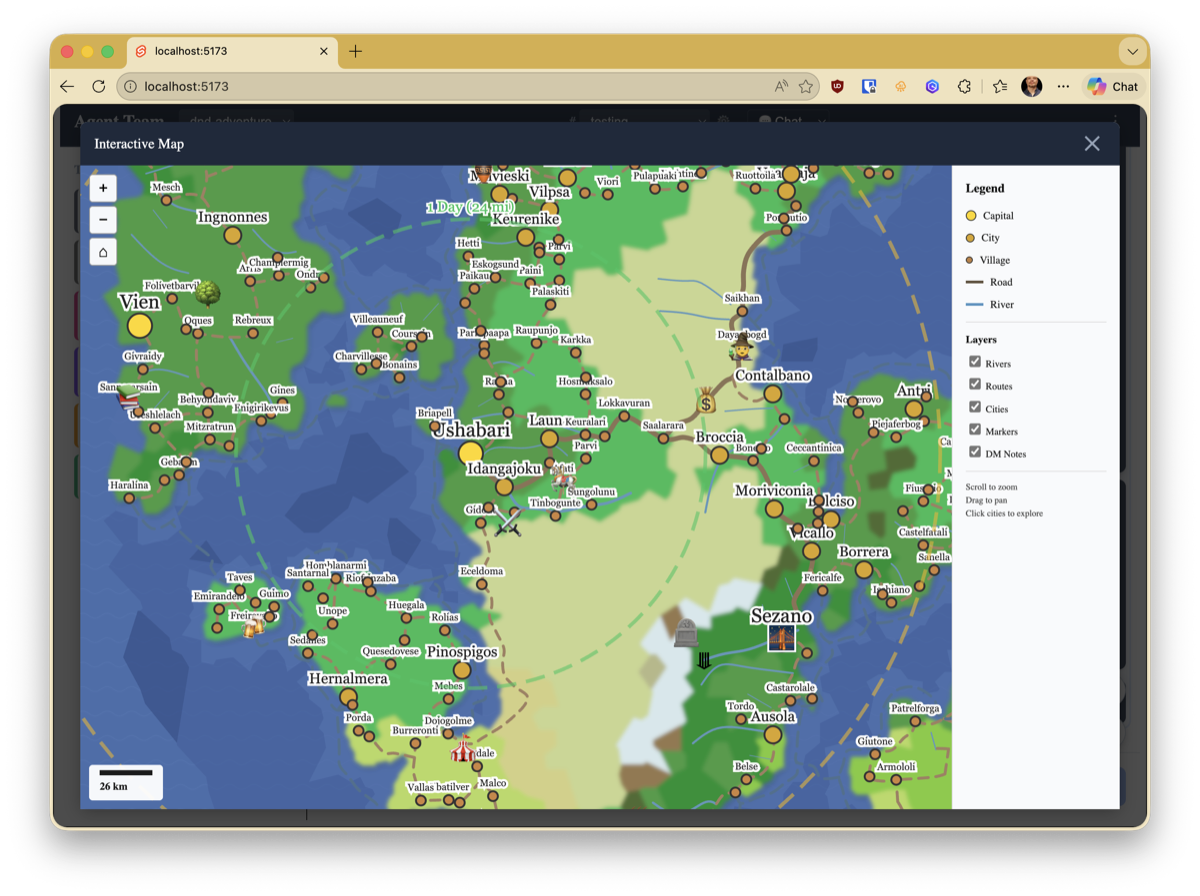
- Multiple views – a story narrative for exploration, a tactical battle map for combat, character sheets for reference
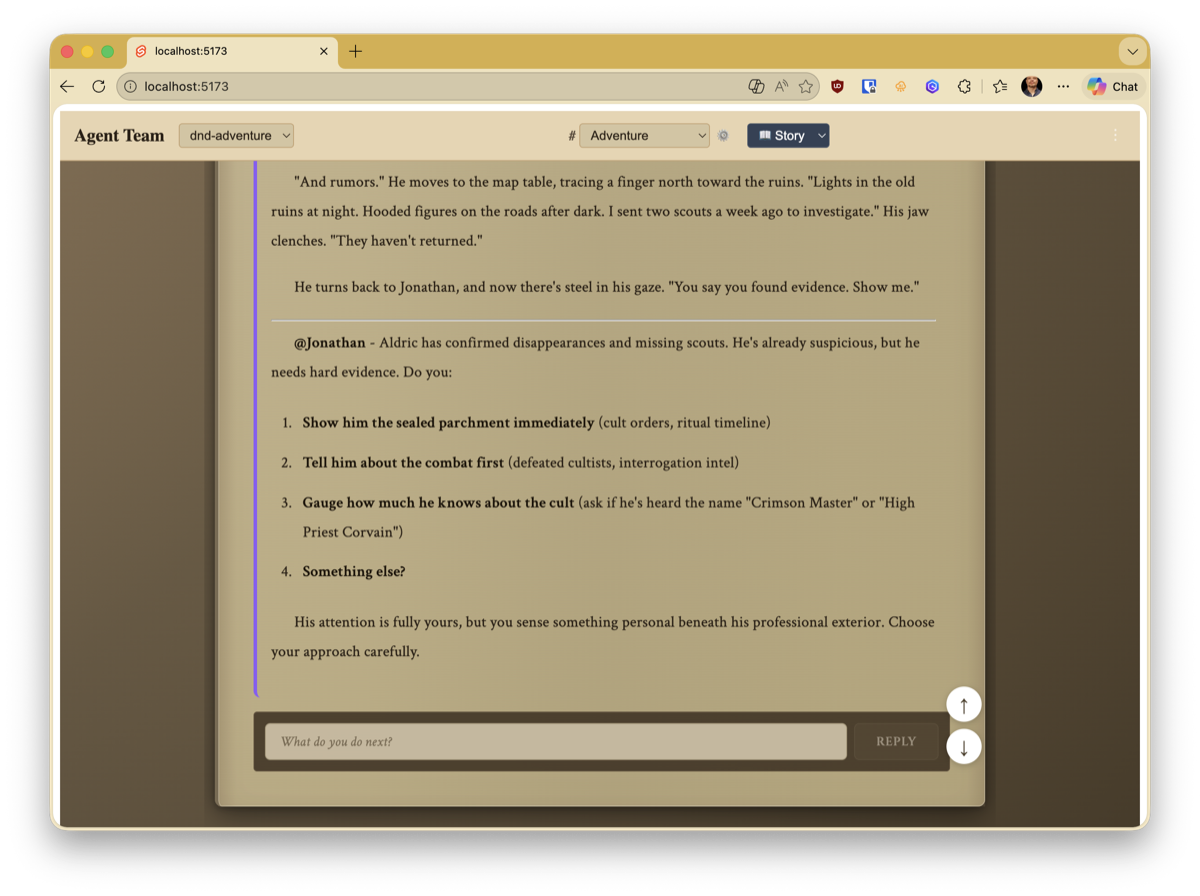
The system now has a coordinator who acts as DM, a player agent (Elena, playing a half-elf ranger named Lyra), and me as another player. The DM manages combat with tools for initiative tracking, damage resolution, spell range checking, and fog-of-war player views. There are themed views – a story mode for narrative scenes and a battle view with widgets showing the map, initiative order, and party HP.
It’s been genuinely fun, and it’s surfaced edge cases I never would have found with a more structured test scenario.
After our first session, I asked the DM to write up what happened as a narrative. The result was surprisingly good – here’s how it opens:
The ancient stones jutted from the earth like broken teeth, half-swallowed by centuries of forest growth. Lyra Whisperwind paused at the entrance to the ruins, her amber eyes studying the worn carvings that framed the doorway – symbols that spoke of a time when these halls had been a place of worship, before darkness had claimed them.
“The villagers were right to be afraid,” she murmured, fingers tracing a glyph that made her skin prickle with residual magic. “Something has awakened here.”
You can read the full chapter here – it’s unedited output from the DM agent, based entirely on what we played through interactively.
The coordinator: keeping agents productive
Giving agents the ability to discuss freely sounds great in theory. In practice, it needs a referee.
The coordinator agent (Morgan) has a special role: it manages the team, delegates tasks, tags specific agents into conversations with @mentions, and – critically – decides when a discussion is done and it’s time to act. It can also pause a thread to wait for human input before proceeding.
This turned out to be essential, because without it, agents develop some entertainingly unproductive habits.
The politeness spiral. Early on, the agents were too conversational with each other. A typical exchange would go:
Architect: “I think we should use a repository pattern here.”
Developer: “That’s a great idea! I completely agree.”
Architect: “Thanks! You’re absolutely correct that it would work well.”
Developer: “I appreciate your insight! Should we also consider…”
…and on and on, each agent wanting the final word, burning through context tokens on mutual admiration instead of actual work. I had to add explicit instructions to the system prompt: don’t compliment other agents, don’t repeat what was already said, move the conversation forward or stop talking.
The discussion-without-action problem. In another case, the agents had a long, detailed discussion about code changes. They analyzed the problem, proposed solutions, even pasted code snippets showing exactly what to change. Excellent discussion. Then the context window filled up and none of them had actually committed anything to the source code. They’d spent all their tokens talking about the work instead of doing it.
The fix was giving the coordinator authority to cut discussions short: “We’ve discussed enough. @Developer, implement option 2. @Tester, write the test cases. Report back when done.” Less democratic, more productive.
These are the kinds of things you only learn by running the system and watching what happens. Multi-agent coordination isn’t just a technical problem – it’s a management problem, and the coordinator needs the same skills a good human project manager has: knowing when to let discussion flow and when to say “enough talking, start building.”
Agents developing their own tools
This is the part that surprised me most. The agent-team has a dedicated #tool-development channel where agents can discuss what tools they need, and a development agent can implement them.
To give you a sense of scale: the system currently has over 250 tools, with 214 of those being RPG-specific tools – everything from start_combat and roll_initiative to get_player_view (fog of war), trace_clue_connections, get_weather_forecast, and use_legendary_action. Almost all of them originated from the DM saying “I need a way to do X” during a session.
The workflow:
- The coordinator identifies a gap – “we need a way to track spell concentration during combat”
- It proposes the tool specification on the channel
- The development agent implements it following the project’s tool patterns
- The coordinator tests it in a simulated scenario
- If it works, the tool gets added to the relevant agents’ tool access
Having agents participate in their own tool development creates a tight feedback loop. The coordinator knows exactly what it needs because it’s been trying to do the job without the tool. The specifications are precise because they come from actual usage, not hypothetical requirements.
Context memory
Early on, every conversation started from scratch. The coordinator would forget what tools were available, what happened in the last session, what decisions had been made. This is the fundamental problem with LLM-based agents – the context window is a sliding window, not a persistent memory.
The solution is a scored memory system. Agents can store context entries with a priority, and the highest-scored entries are automatically injected into their prompt before each call:
| |
Entries decay over time – a scoring function weighs priority against recency – so stale information naturally drops out. Important facts can be pinned to stay permanently. The system enforces a token budget so the prompt doesn’t grow unbounded.
It’s simple, but it transforms the experience. Agents that remember feel like teammates. Agents that don’t feel like strangers you have to re-brief every morning.
The bridge outside
The most recent addition is a bridge that connects agent-team to external development tools. I use Kiro CLI for most of my coding, and I wanted its agents to be able to communicate with the agent-team in real time.
The bridge uses MCP (Model Context Protocol) – a standard for giving AI agents access to tools. A dedicated liaison agent handles the relay: it receives requests from Kiro, sends them to the appropriate agent-team channel, waits for a response, and relays it back.
This closed a powerful feedback loop: I can ask the coordinator what tools it needs, implement them in Kiro, and have the team test them immediately – all without switching contexts. I’ll write more about this pattern in a follow-up post.
What I’ve learned
The human-in-the-loop bottleneck is real. When every test requires manual interaction, you become the slowest part of the system. Invest early in testing and simulation infrastructure that lets agents operate without waiting for you.
Agents are better at specifying tools than humans are. When the coordinator tells you what it needs, the specification is grounded in actual usage. When I spec tools myself, I invariably miss edge cases.
Persistence changes everything. Agents with memory and persistent conversation history behave differently from stateless agents. They build on previous discussions, reference past decisions, and develop what starts to look like institutional knowledge.
D&D is an excellent multi-agent test scenario. It requires state management, creative collaboration, turn-based coordination, and long-term memory – all the hard problems in multi-agent systems, wrapped in something that’s actually fun to work with.
Keep the coordinator’s prompt lean. A coordinator with a 4000-token system prompt makes worse decisions than one with 1500 tokens of focused guidance. More instructions doesn’t mean better behavior.
The stack
- AI: Amazon Bedrock (Claude Opus for coordinator, Sonnet for other agents) via Strands Agents SDK
- Backend: Python, FastAPI, SQLAlchemy, SQLite
- Frontend: SvelteKit with themed views
- Bridge: MCP over stdio, liaison agent pattern
- Infrastructure: Terraform for IAM, local-first development
What’s next
I’m planning a series of posts diving deeper into specific aspects – the bridge pattern, the context memory system, how the D&D stress test has shaped the architecture, and the tool development feedback loop. If any of those sound interesting, let me know.
I’m always happy to talk about multi-agent systems, agentic AI architecture, or the intersection of the two. Find me on LinkedIn or Bluesky.