
I wanted to see what happens when you give a team of AI agents a codebase and let them work on it with minimal supervision. Not a demo with three tasks, but a real, ongoing development project running for weeks.
The result is ai-team – a multi-agent coordination system where specialized AI agents pick up tasks, write code in isolated git branches, get reviewed and tested by other agents, and merge their work back. As I write this, the system has processed over 1,000 task units (“beads”) and is currently building its own knowledge graph feature.
Yes, it’s building itself. I’ll get to that.
How it started
I built the skeleton framework directly with kiro-cli – the scheduler, spawner, memory, and basic bead model. Once the coordination loop was functional enough to process beads, I started feeding it planning beads through kiro-cli. The lead agent would break those down into implementation, test, and review beads, and the system would execute them.
As the TUI dashboard matured (built by the system itself, naturally), I shifted to using it as the primary interface for creating planning beads. The workflow now is: I type a goal into the TUI, the lead breaks it into a sequence of beads with dependencies, and the scheduler takes over.
The bead model
The task model is inspired by Steve Yegge’s beads – a dependency-aware graph for tracking agent work. Every unit of work is a bead with a type that determines which agent handles it:
| Type | Agent | What happens |
|---|---|---|
| plan | lead | Break a goal into beads |
| design | architect | Architecture decisions |
| implement | builder | Write code |
| test | tester | Write and run tests |
| review | reviewer | Review the diff |
| bug | builder | Fix a defect |
| investigate | scout | Explore and research |
| docs | writer | Documentation |
| research | researcher | Deep research tasks |
Beads have dependencies – a test bead is blocked until its implement bead completes. The scheduler respects these automatically and runs independent beads in parallel. The dashboard shows the current state: ready, running, blocked, done.
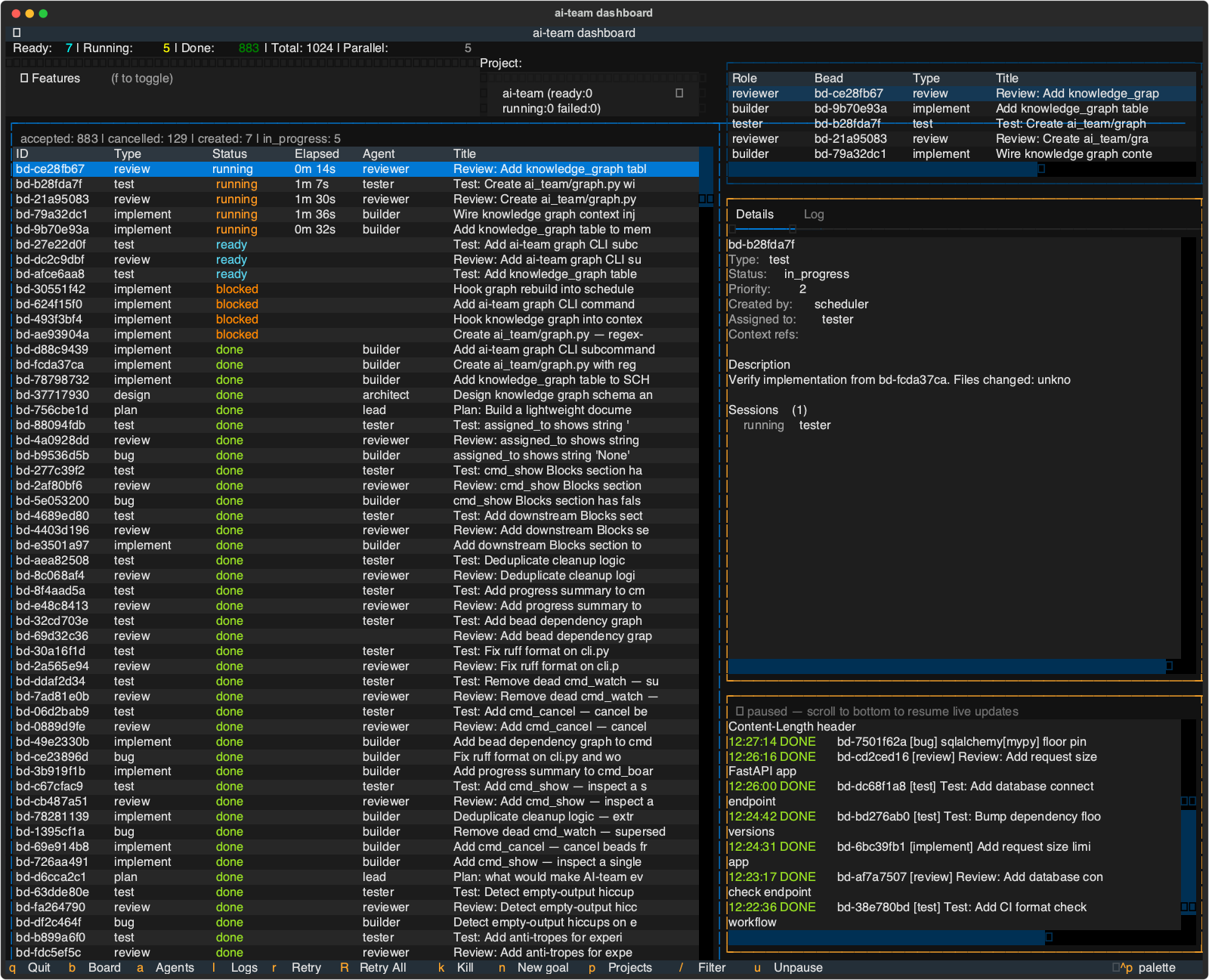
The bead model also solves a problem I hit with every agent-to-agent communication framework I evaluated: they’re all kludgy. Direct message passing between agents creates tight coupling and coordination overhead. With beads, agents don’t talk to each other at all – they communicate through the linked bead graph. A builder completes a bead, a review bead gets unblocked, the reviewer picks it up. The “conversation” is the chain of beads and their outputs, not a chat thread.
Git worktrees: how agents don’t step on each other
This was the key architectural decision. Every write-agent (builder, tester) gets its own git worktree on a dedicated branch. They can modify files freely without conflicting with other agents working on different beads.
When a bead completes, the system merges the worktree branch back. If there’s a merge conflict, it retries with the updated base. If it fails repeatedly, it escalates to the lead for triage.
Read-only agents (reviewer, scout) work against the main repo directly since they don’t modify files.
This means you can run 4-5 agents in parallel on the same codebase without coordination overhead. The git history stays clean because each bead is a focused change on its own branch.
Security: least privilege by default
Each agent role gets a scoped set of tool permissions. A builder can read, write, grep, and run shell commands. A reviewer can only read and grep. A scout can read and grep but nothing else.
When the system introduces a new agent role, it automatically tunes the permissions to the minimum set that lets the agent do its job. Projects can override these defaults, but the baseline is restrictive.
This matters because these agents run real shell commands on a real codebase. You don’t want a reviewer accidentally running rm -rf or a scout modifying source files.
kiro-cli as the agent runtime
Each agent is an independent kiro-cli session. I chose kiro-cli because it has built-in MCP support and good tool-level security configuration – you can control exactly which tools each agent can use and what shell commands they’re allowed to run.
The spawner starts a kiro-cli session with the right context bundle: project docs, relevant decisions, the specific bead to work on, and the current team state. When the session completes, the spawner captures the output and updates the bead status.
Agents don’t share context windows. They communicate through SQLite-backed memory – shared knowledge, decisions, and the bead board itself. This avoids the context degradation problem where long-running agents get confused by accumulated conversation history.
Long-term memory
Agents build up knowledge over time. When a builder discovers that a particular test pattern works well, or an architect makes a design decision, that gets stored in the project’s memory database. Future agents working on related beads get this context injected automatically.
The memory is structured – not just a blob of text, but typed entries (decisions, patterns, conventions, known issues) that can be queried and filtered. The system is currently building knowledge graph support to make this even more useful for non-coding projects where the relationships between entities matter.
What 1,000 beads taught me
After watching the system process over 1,000 beads, a few things stand out:
The failure rate is lower than I expected. Most beads complete successfully on the first attempt. When they fail, it’s usually because the bead description was ambiguous, not because the agent made a mistake. Clear task descriptions matter more than clever prompting.
Review beads catch real issues. The reviewer agent finds bugs, style violations, and missing edge cases that the builder missed. Having a separate agent review the diff – rather than the same agent checking its own work – makes a real difference.
The system gets better at its own codebase over time. As more decisions and patterns accumulate in memory, agents make more consistent choices. The 500th bead runs smoother than the 50th because the agents have more context about how this particular project works.
Parallelism has diminishing returns past 4-5 agents. With more agents, merge conflicts increase and the scheduler spends more time coordinating. 4-5 parallel agents seems to be the sweet spot for a single codebase.
Beyond code
The system started as a coding tool, but the architecture is general enough for other types of work. I’m expanding it to support:
- Jupyter notebooks for data analysis and research tasks
- Web browsing (internal and external) for research agents
- Slack and Outlook access so agents can find relevant project context – meeting notes, design discussions, stakeholder requirements
- AST tree analysis to give agents a structural view of the codebase without reading every file
The knowledge graph work happening right now is specifically aimed at non-coding projects – research, analysis, writing – where understanding relationships between entities is more important than understanding code structure.
Why beads solve context rot
One of the biggest problems with long-running AI agents is context rot – the longer a session runs, the worse the agent performs as its context window fills up with stale information. Every multi-agent system I’ve built before has hit this wall.
Beads sidestep the problem entirely. Each bead gets a fresh kiro-cli session. The agent starts clean, receives only the context it needs for that specific task (project docs, relevant decisions, the bead description, AST structure of affected files), does the work, and exits. No accumulated conversation history, no degraded performance over time.
The long-term memory and AST tree analysis compensate for the lack of session continuity. An agent working on bead #900 doesn’t need to remember what happened in bead #50 – it gets the relevant knowledge entries and code structure injected at startup. Fresh context, informed by history.
The coordination loop
Beads don’t appear out of thin air. There’s a continuous loop that keeps the system moving:
- An external agent (or a human) creates high-level goals
- The lead agent breaks goals into beads with dependencies
- The scheduler picks ready beads and routes them to available agents
- Completed beads automatically spawn follow-up work – an implement bead creates review and test beads
- The loop keeps running until no ready beads remain
There’s also a background “Ralph loop” that monitors the board and nudges things along – retrying stuck beads, escalating repeated failures, and keeping the pipeline flowing. The goal is minimal human intervention: set a direction, watch the board, step in only when something genuinely needs a decision.
The system supports multiple projects running simultaneously, each with its own set of agents, memory database, and parallelism settings. The TUI dashboard has a project selector so you can switch between boards. Each project is fully independent – different codebases, different agent configurations, different bead queues – but managed from the same tool.
The meta moment
The part that still amuses me: the system is building itself. The TUI dashboard, the knowledge graph, the bead dependency visualization – all built by ai-team agents working on the ai-team codebase. The lead plans the work, builders implement it, testers verify it, reviewers check it.
I give it a goal like “add a progress summary to the board command” and come back to find the feature implemented, tested, reviewed, and merged. Sometimes I disagree with an architectural choice and create a bug bead to fix it. Sometimes the reviewer catches something the builder missed and a bug bead gets auto-created. The feedback loop is tight.
It’s not fully autonomous – I still set direction, review the overall architecture, and handle the occasional bead that gets stuck in a loop. But the ratio of my input to useful output keeps improving.
The stack
- Python 3.11+, single package
- SQLite (WAL mode) for all state – one file per project
- kiro-cli for agent execution with MCP tool support
- Textual for the TUI dashboard
- Git worktrees for parallel agent isolation
This is a personal project, not yet open source. If you’re building multi-agent development systems or have thoughts on the approach, I’d like to hear about it – find me on LinkedIn or Bluesky.