Three weeks ago I wrote about building a self-coordinating AI development team. At that point the system had processed about 1,000 beads and was starting to feel like more than a prototype.
Since then, the bead counter passed 3,400. The system has been running almost continuously on my laptop, building features, fixing its own bugs, and – most instructively – breaking in ways I didn’t anticipate.
This is what I learned.
The numbers
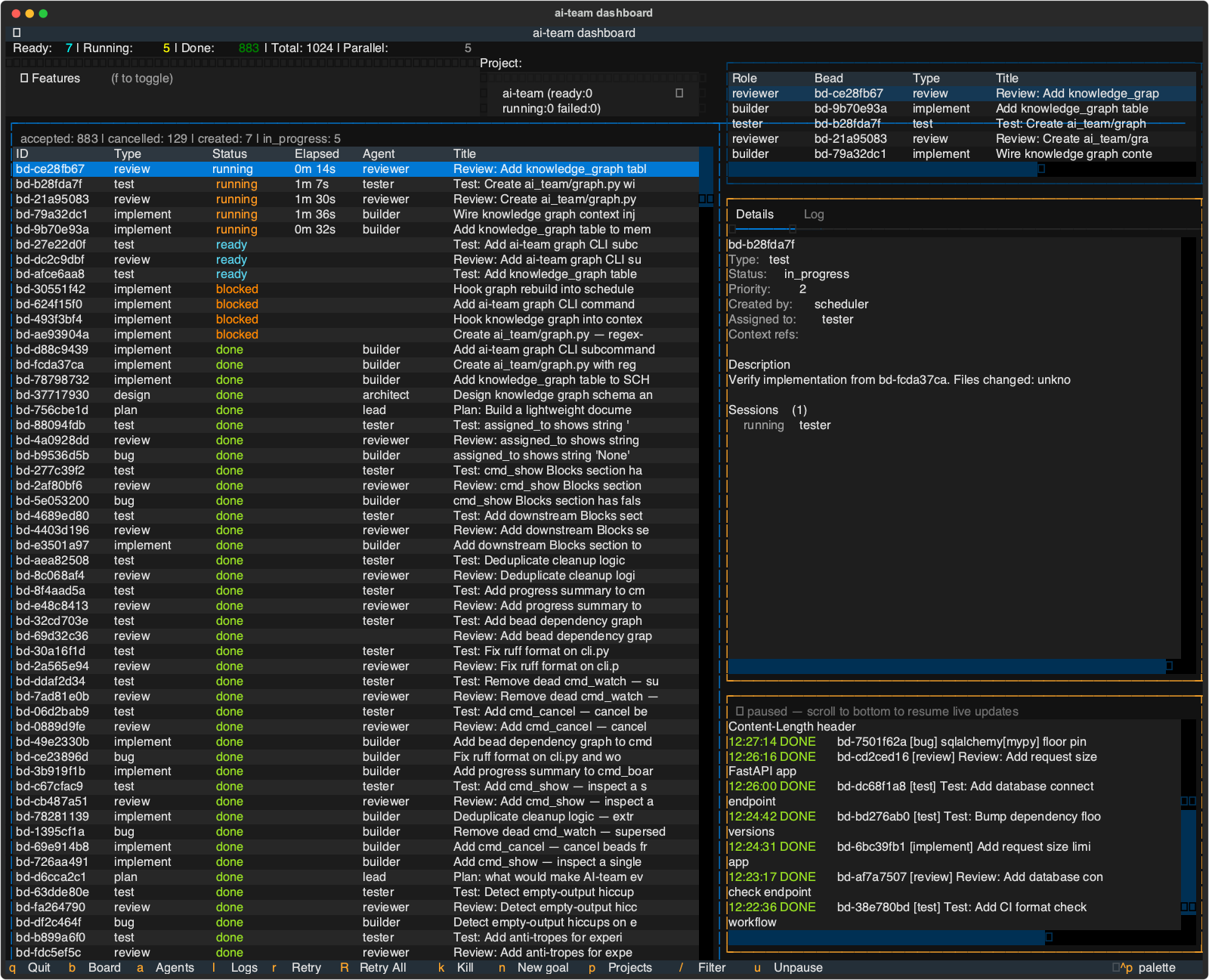
When I wrote the first post, the stats looked like this: ~1,000 beads, a handful of agent roles, basic scheduling. Here’s where things stand now:
- 3,466 beads processed (3,236 done)
- 2,900+ tests across 370+ test files
- 10 agent roles, each with scoped tool permissions
- 485 builder sessions at 96% success rate
The builder success rate is the number I watch most closely. Early on it hovered around 85% – agents would fail on merge conflicts, miss edge cases, or time out. The self-healing mechanisms (auto-retry from fresh branches, lint auto-fix, escalation to lead for triage) brought that up steadily.
The laptop ate my database
The most painful lesson had nothing to do with agents or prompts. It was about SQLite and laptop sleep.
ai-team stores all state in a single SQLite database per project, running in WAL mode. Multiple processes access it simultaneously – the coordination loop, the TUI dashboard, and the CLI. WAL mode handles concurrent readers and writers well. On paper.
The problem is macOS. When your laptop sleeps, the OS suspends processes mid-operation. Apple’s bundled SQLite uses F_BARRIERFSYNC instead of F_FULLFSYNC, which means even with PRAGMA synchronous=FULL, hardware write caches don’t get flushed. Close the lid at the wrong moment and you wake up to a corrupted B-tree.
The corruption is insidious. Reads from undamaged pages return normally. The coordination loop prints “Idle” every 30 seconds, looking perfectly healthy, while the database index is broken underneath. New beads written by the CLI land in the WAL but the loop’s queries walk a corrupted index and return empty results. The system appears to work but nothing actually moves.
I hit this ten times over eleven days. Here’s the progression of fixes:
Phase 1 – basic recovery. Added a recover_db function that rebuilds the database from SQLite’s .recover output when a DatabaseError is caught. Nightly backups via a scheduled bead. This got the system running again after corruption, but only when a query happened to hit a damaged page. Silent corruption could persist for hours.
Phase 2 – sleep detection. The run loop now compares wall clock vs monotonic clock to detect gaps longer than 30 seconds. On wake, it invalidates all database connections and reconciles stale file locks. Post-wake state was cleaner, but corruption still happened because the underlying fsync was insufficient.
Phase 3 – the actual fix. A research bead dug into the root cause and came back with the answer: PRAGMA fullfsync=ON. This forces fcntl(F_FULLFSYNC) instead of fsync(), actually flushing hardware write caches. About 5-10% write overhead, negligible for this workload.
On top of that: periodic PRAGMA integrity_check every 10 minutes to catch silent corruption early, WAL checkpoint on wake to reduce uncheckpointed data, and verification that recover_db actually produces a clean database before declaring success.
The corruption log stopped growing after deploying fullfsync. If you’re running SQLite in WAL mode on macOS and your process can be suspended – this is the fix.
What the system built while I wasn’t looking
The most interesting beads aren’t the ones I plan. They’re the ones the system creates for itself.
When a builder fails twice on the same bead, the lead agent triages the failure and often creates a new bead to fix the underlying issue. When the watchdog detects an agent role underperforming (session time exceeding the p90 baseline), it creates an investigation bead. When a reviewer flags a pattern that keeps recurring, the lead creates a bead to add it to the project’s conventions.
Some highlights from the last three weeks:
- The TUI chat panel – I typed “add a chat panel for real-time conversation with the lead” and the system designed, implemented, tested, and reviewed it across 8 beads
- Scheduled beads – cron-style recurring tasks (nightly backups, weekly test suites, monthly security audits), built by the system after I described the concept
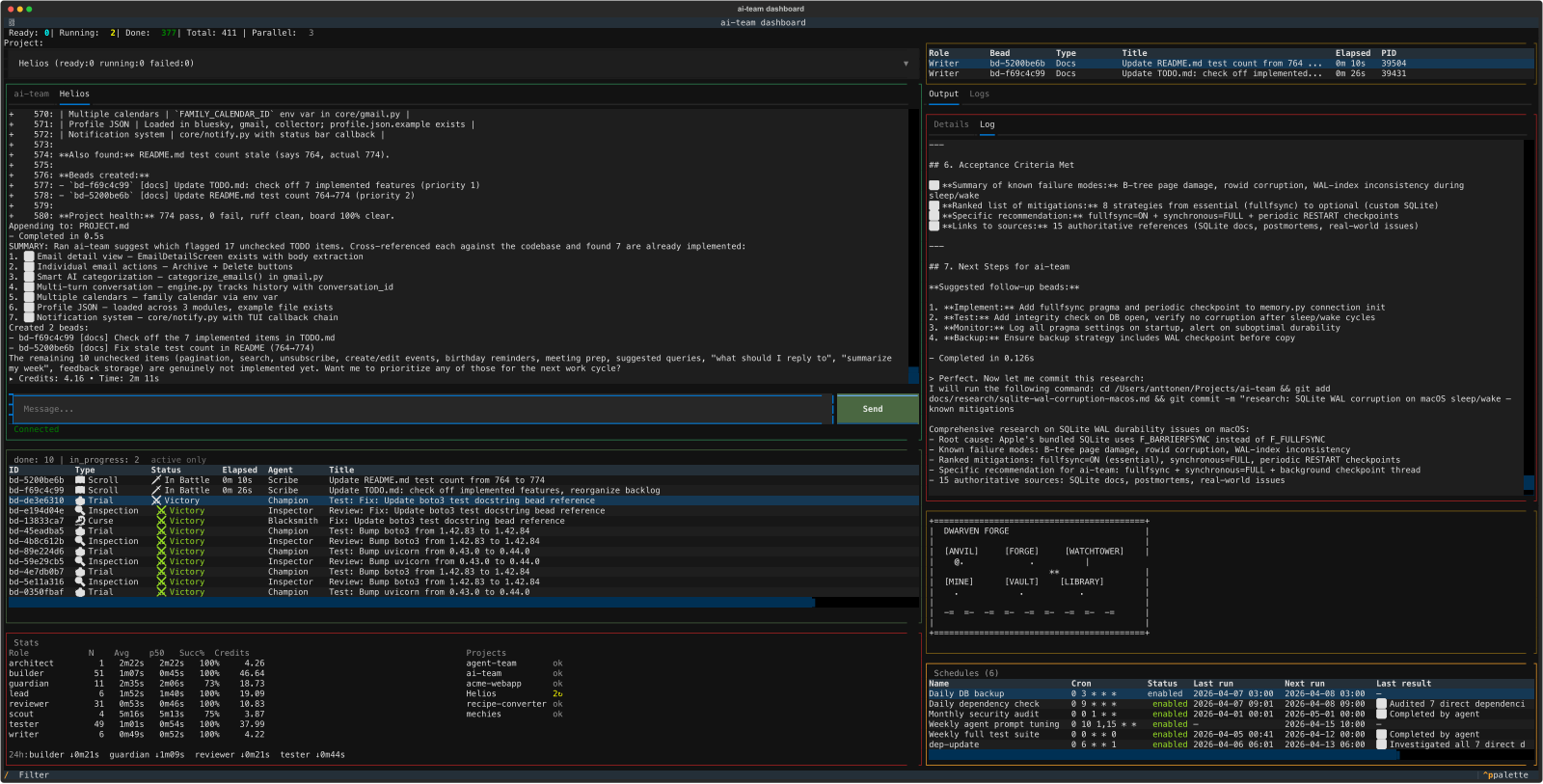
- A skin system with a fantasy theme – a colleague had built something similar for their project, which gave me the idea. I described the concept to ai-team and it handled the entire implementation: themed labels for agent roles and bead types, a color palette system, and the roguelike visualization. The default skin shows a workshop, the fantasy skin turns it into a Dwarven Forge with anvils and forges
- The SQLite resilience fixes described above – the research bead that identified
fullfsyncwas created by the lead after the third corruption event
The clarification cycle helps here. When an agent is confused about a requirement, it pauses the bead and asks instead of guessing. I answer through the TUI chat panel or the CLI, and the agent continues. This means I can give vague goals (“make the database more resilient”) and the system will ask the right questions before committing to an approach.
The roguelike easter egg
At some point the system built itself a roguelike visualization. A little ASCII workshop scene where you can see agents at their workstations:
+------------------------------------------+
| WORKSHOP |
| |
| [DESK] [BENCH] [TERMINAL] |
| @ B . |
| |
| [SHELF] [TABLE] [BOARD] |
| . T . |
| |
| ~~ ~~ ~~ ~~ ~~ ~~ ~~ ~~ ~~ |
| |
+------------------------------------------+
@ is the lead, B is a builder, T is a tester. Empty stations show a dot. The water at the bottom animates. Switch to the fantasy skin and it becomes a Dwarven Forge with an anvil, forge, and watchtower.
It’s completely useless and I love it.
The metadata is the product
After five weeks of continuous operation, the system has accumulated a surprising amount of data about its own performance. Per-role success rates, average session durations, failure patterns, which types of beads take longest, which agent prompts produce the best results.
This enables prompt auto-tuning. The system can look at its own stats – the watchdog already does this for anomaly detection – and adjust how it instructs agents. A builder prompt that leads to 91% success on implement beads but only 78% on bug-fix beads is a signal. The data is there to act on it.
Running something like this for multiple weeks generates metadata that’s genuinely valuable for refinement. You can’t get this from a weekend experiment.
How the work changes
The nature of development has shifted as the system matured. Early on, every bead was about building necessary infrastructure – the scheduler, the memory layer, the merge pipeline. Essential plumbing.
Now the work is more subtle. I point the lead agent towards GitHub repositories and blog posts from people doing interesting work in the multi-agent space and ask it to evaluate what’s worth adopting. The skin system came from a colleague’s project. The bead model came from Steve Yegge. The clarification cycle was inspired by how human teams actually work.
AI-age development is standing on the shoulders of giants, but the climb is incredibly fast. You can go from “that’s a neat idea in someone’s repo” to “it’s implemented, tested, and running in production” in an afternoon. The bottleneck isn’t implementation anymore – it’s taste. Knowing which ideas are worth stealing.
What I’d do differently
Start with fullfsync. The database corruption cost me more debugging time than any agent-related issue. If you’re building anything that stores state in SQLite on a laptop, set PRAGMA fullfsync=ON from day one.
Smaller beads. The system works best when beads are small and focused – a single function, a single test file, a single config change. Large beads (touching 5+ files) have a noticeably lower success rate because merge conflicts become more likely and the agent has to hold more context.
Trust the review cycle. Early on I’d intervene when I saw a builder making a questionable choice. Now I let the reviewer catch it. The reviewer agent has a paranoid checklist and catches things I’d miss – unused imports, missing error handling, test assertions that don’t actually test anything.
What’s next
The system is still in active development – by itself, mostly. I’m considering opening it to beta testers. If you’re experimenting with multi-agent development and want to try running a team of agents on your own codebase, reach out on LinkedIn or Bluesky. No promises on timelines, but I’d like to see how it works for someone other than me.
The first post covers the architecture and bead model in detail if you want the full picture.